
Blog
Feb 11, 2020
Daan T. Bakker

Voordat ik dieper inga op allerlei definities en verklaringen, wil ik u graag een geheim verklappen: Als het om muziek gaat, ben ik een beetje een nerd. Vandaar de titel van deze blog, die is geïnspireerd op het beroemde album 'Appetite for Destruction' uit 1987 van Guns N' Roses. Dit album kreeg in de muziekindustrie in eerste instantie weinig aandacht; pas later volgde de erkenning dat het album enkele geweldige songs bevat. En dat sluit goed aan bij het punt dat ik wil maken: dat het belangrijk is dat verzekeringsmaatschappijen de link leggen tussen 'precision' (vaak aangeduid als succespercentage) en hun risicobereidheid. Als ze dit niet doen, lopen ze kans later belangrijke informatie mis te lopen. Anders gezegd: dit is een zelfdestructieve manier van werken die uiteindelijk indruist tegen hun eigen belang.
De weg vrijmaken voor 100% precision
Laten we beginnen met enkele termen die we gebruiken om fraude correct te classificeren:
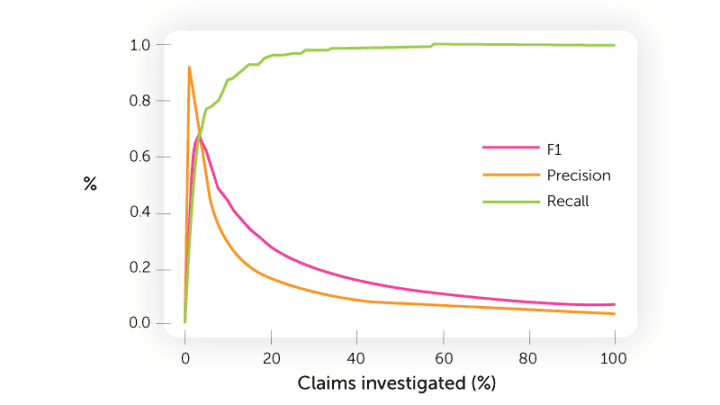
F1:twee maal precision maal recall gedeeld door precision plus recall
Precision (precisie): het aantal correct geclassificeerde claims gedeeld door het aantal ingezonden claims Recall (opbrengst/vangst): het aantal correct geclassificeerde claims gedeeld door het totale aantal fraudegevallen in een historische dataset
Uit ons recente onderzoek blijkt dat verzekeringsprofessionals geloven dat 18% van de claims een element van fraude bevatten. Als je een set van 200.000 claims bekijkt, kom je ongetwijfeld fraude op het spoor. Als je, met behulp van een fraudedetectiemodel, slechts een geval classificeert, vind je mogelijk alleen het meest voor de hand liggende geval. Vanuit het oogpunt van data science zeggen we dat er een kans van 99,9% bestaat dat het hier om een fraudegeval gaat. De precision (of het succespercentage) zou in dit geval 100% zijn. Dat is een succespercentage dat elke schade-expert maar wat graag zou willen laten zien aan diens leidinggevende.
Oog voor de eerlijke klant
Waarom is dit toch niet wenselijk? In het voorbeeld hierboven zou het merendeel van de fraudeurs over het hoofd worden gezien. Dat komt doordat we denken dat er sprake is van een precision van 100% en dat alle fraude wordt geclassificeerd, terwijl in werkelijkheid slechts 1 van alle 200.000 claims door het systeem wordt gemarkeerd. Als je alle fraudegevallen wilt opsporen, moet je alle 200.000 claims classificeren. Dan heb je een nultolerantiestrategie, maar de afdeling fraudeondezoek zou worden overspoeld door foutpositieve resultaten. Aangezien het merendeel van de klanten betrouwbaar is, hebben zij recht op snelle uitbetaling zonder onnodige vertragingen door fraudeonderzoek. Als je een goede selectie wilt maken van gevallen die in aanmerking komen voor nader onderzoek, moet je selectiever zijn bij het classificeren van frauduleuze gevallen.
De juiste balans vinden
Daarom zijn wij van mening dat het essentieel is om samen te werken met onze klanten, om precision af te stemmen op risicobereidheid. Onze krachtige AI-technieken zoals voorspellende modellen, netwerkanalyse en tekstmining in combinatie met meer dan 600 kant-en-klare risico- en fraude-indicatoren kunnen elke mogelijke vorm van fraude markeren.
Als de capaciteit van de afdeling fraudeonderzoek beperkt is, kunnen we het systeem nauwkeuriger afstemmen op een hogere precision, zodat alleen de meest riskante gevallen worden gemarkeerd voor verder onderzoek. Bij voldoende capaciteit en goedwerkende processen voor het volgen van alerts wil je juist een lagere precision en een hogere recall.
Als er meer claims worden onderzocht, betekent dit ook dat onze modellen meer feedback krijgen van de afdeling speciale zaken. Met deze feedback worden onze modellen automatisch opnieuw "getraind", waardoor de precision uiteindelijk toeneemt. Dit creëert een positieve spiraal van feedback, waar ons fraudedetectiepercentage enorm van profiteert. Het vinden van de juiste balans tussen precision en recall is voor onze klanten dus bijzonder waardevol.
Het is deze uitdaging die onze data scientists elke dag opnieuw aangaan bij de implementatie van FRISS, en het geeft mij persoonlijk zeer veel voldoening om dit op de juiste manier te doen. Naast mijn collega's bestoken met slechte muziekgrapjes natuurlijk...
Over de auteur
Daan Bakker werkt als data scientist bij FRISS en zijn professionele carrière draait om fraudedetectie. Daan en zijn data science-collega's houden zich dagelijks bezig met het verbeteren van de producten en algoritmen van FRISS, met als enige doel om de verzekeringswereld voor iedereen eerlijker te maken.